Query the Database
Contents
Timber provides three ways to query a file stored in
Timber
XQuery
Timber supports queries in standard XQuery. Each query in XQuery is composed of a sequence of XQuery expressions, including path expressions used to locate nodes in XML structures, element constructors for constructing XML structures with, and FLWOR expressions for combining and restructuring information from XML documents, sorting, and conditional expressions, and quantified expressions. For more information about the XQuery specification, see XQuery 1.0.
Timber supports a wide range of features in XQuery. Specifically, Timber supports any queries satisfying XQuery Fragment Supported. In addition, Timber also supports XQuery with updates, and Schema-Free XQuery. Please note that XQuery is case-sensitive, and all XQuery keywords (such as for, let) and function names should be in lower case.
As an illustration, following are two example queries supported by Timber, including simple selection query and complex nested queries on XML document sbook.xml.
Example1: Simple query:
return the title of books whose prices are between 20 and 60.
|
for
$b in document("sbook.xml")//book where
$b/price < 60 and $b/price > 20 return $b/title |
Example 2: Nested query: for books whose price is between 20 and 60, return its title and articles published in the same year as the book
|
for
$b in document("sbook.xml")//book where
$b/price < 60 and $b/price > 20 return
<result> {$b/title} {for $k in
document("sbook.xml")/books/article where $b/year = $k/year return $k } </result> |
Important Notes: The nested queries must be connected
with the outer part via a join (either value join or structural indicated by a
path). Else it cannot be supported by our system
Example 3: Unsupported Nested query
|
let
$c := for $k document("sbook.xml")//book return $k return $c |
XQuery with Updates
Standard XQuery syntax does not allow updates to the database. Timber extends XQuery to support updates to the database via queries, including deletion, update/modify, insertion of elements, and insertion of attributes. In addition to the update functions added to XQuery, Timber also allows the user to append an XML document to a file that is alread loaded, via the append operation (accessible from the command line). When many updates have been performed, query performance will be increased by performing a reorganize on the file (so that all nodes will be stored in "document order", as they are when data is initially loaded into Timber).
1.
General Principles of our XQuery Update Functions
All functions update nodes that map to `FOR' bound variables. So the
semantics follow the logic of XQuery on `FOR' bindings. Althought
batch updates are supported, note that the variable bindings occur
before the updates start to be processed. In other words, any
inserted nodes will not be seen by succeeding update function calls
(while deleted and modified nodes will affect subsequent updates in
the same query). A different query must be issued for newly inserted
nodes to be accessed.
2. Update Functions
In
addition to the update methods listed below, we also provide an append
method that is accessible from the command line. This will
take an XML file and (efficiently) append it to a currently loaded
file. All indices will be updated appropriately. Note that if
the file contains an overflow portion before appending, the entire
appended document will end up in the overflow portion. This is not
advisable for large documents, and the user should perform a
reorganize before appending large documents.
Appending a document new.xml (that exists in a Data directory) to
the document sbook.xml (that is already loaded into Timber) is
executed as follows:
timber -m
append -d Data\new.xml -a sbook.xml
Update functions of Timber along with example usages are listed as below.
1) Deletion:
timber-delete(<var> | <var>/text())
This function accepts as an argument <var> a `FOR' bound
variable. It deletes from the database all nodes that correspond to
this variable. If the nodes are elements, then the subtrees rooted
at those nodes are also deleted. To delete only the content (text)
use /text() after the variable.
Example 4-a.
Select
all books and delete the authors.
|
for $b in
document("sbook.xml")//book |
NOTE:
If the last line was: return timber-delete($a/text()) only the
content (text) of the author elements would be removed.
Example 4-b. Select
all books and delete the author and content of price elements.
|
for $b in
document("sbook.xml")//book |
NOTE: according to the `FOR' binding semantics in xquery, a book with an author but no price will not be selected.
2) Update:
timber-update(<var>, <Value> | <SP> |
Aggregate(<SP>) )
This function accepts a `FOR' bound variable to indicate the nodes
whose content is to be updated. The second argument can be a
constant value (string or number), a path to some other selected
element from the database or an aggregate function. The function
will set the content of the nodes bound by the input variable to the
what is specified at the right input path. An update will not create
an element, it will only update its content if it exists.
NOTE: If the second
argument is a path to another selected element (such as $b/price),
it is possible for this path to map to more than one node, in a
single result (i.e. witness tree). If this is the case, only the
first of such mappings will be used to assign a value to <var>,
and a warning will be issued indicating this. This behavior
applies to all other XQuery update methods defined in this document
as well.)
Example 5-a.
Select
all books and set the content of its
author to "Stelios".
|
for $b in
document("sbook.xml")//book |
Example 5-b. Set all of the book authors to be equal to the book's publisher attribute.
|
for $b in
document("sbook.xml")//book |
Example 5-c. Set each book's id attribute to be equal to the book's isbn.
|
for $b in
document("sbook.xml")//book |
NOTE: if there is no associated isbn for a given book, the id attribute will be updated with its value equal to "".
Example 5-d. Select all books, set attribute author to "Stelios". set price to 5, set name equal to the content of title and set authorcount equals to the count of all authors.
|
for $b in
document("sbook.xml")//book |
3)
Insertion of Element
: timber-insertelement( <SP>, ElementTag,
<Value> | <SP> | Aggregate(<SP>), <attrCont>*),
where <attrCont> ::= AttributeTag, (<Value> | <SP>
| Aggregate(<SP>)
This function inserts a constructed element under the nodes
specified by the input `FOR' bound variable. The new element is
specified by a tag and its content descriptor (constant value for
string or number,or a path pointing to some other node, or an
aggregate function). An optional list of attributes is also
supported.
Example 6-a. Select all books, and under each author insert an element with tag equals "name" and content equals "Stelios".
|
for $b in
document("sbook.xml")//book |
Example 6-b. Select all books with editor equals "Stelios", insert an element with tag = "flag" and empty content.
|
for $b in
document("sbook.xml")//book |
Example 6-c.
Select all books and insert under each author an
element with tag "price" and content "5", create
an attibute named "avg" and content equal to the average
price of the book, and an attribute "name" with content
equal to the editor of the book.
|
for $b in
document("sbook.xml")/books/book |
4)
Insertion of
Attribute: timber-insertattribute( <var>, AttributeTag,
<Value> | <SP> | Aggregate(<SP>))
Similar in concept with insert element, this function will insert an
attribute under the node specified by the input variable binding.
The attribute tag is given and the content can be a constant value
or set equal to some other node in the database, or the result of an
aggregate function.
Example
7. Select
all books with editor equals "Stelios", under each
chapter
insert an attribute with tag "num" and no associated
value.
|
for
$b in document("sbook.xml")//book |
Timber provides update functionality by
extending the XQuery language. When no updates have been
performed on a Timber volume, all nodes for a document are laid out
on the disk in document order. This is a key factor in
efficient query execution. When updates are performed we may
be required to put nodes into a separate unordered overflow portion
of the file. This happens when we insert new nodes, and when when a
node is modified so that its new value is larger than its previously
stored value. If the overflow portion is large enough, query
performance will suffer. To alleviate this problem, Timber
provides a reorganize function that will take a file containing an
overflow portion, and lay all of the nodes out on disk in document
order.
Reorganizing the file from the command line is executed as follows,
where the document sbook.xml is the file to reorganize.:
timber -m reorganize -d sbook.xml
Schema-free XQuery
Writing queries in standard XQuery requires extensive knowledge of the document structure (i.e., the document schema) in order to write the correct path expressions used to locate nodes in XML structures. Even for queries as simple as the one in Example 1, the user must at least know that nodes priceand titleare children of nodes book in order to correctly write the queries.
In Timber, we provide a function timber-mlca()to allow users with limited knowledge of document structure, to be able to pose complex queries and get meaningful results. Specifically, the function timber-mlca() return the Meaningful Lowest Common Ancestor (MLCA) of the variables inside the function; any variables sharing the same non-empty MLCA are regarded as meaningfully related to each other. More details about Schema-Free XQuery can be found here.
The following are the corresponding schema-free queries for the previous example queries in XQuery, when the user only has the knowledge of tag names and values.
Example 8. Simple schema-free query (corresponding to the simple query in Example 1)
|
for
$d in timber-mlca($b, document("sbook.xml")//book, $p,
document("sbook.xml")// price,
$t,document("sbook.xml")//title) where
$p < 60 and $p > 20 return $t |
Example 9. Complex schema-free query (corresponding to the simple query in Example 2)
|
for
$d1 in timber-mlca($b,document("sbook.xml")//book,
$p1,document("sbook.xml")//price,$y1,
document("sbook.xml")//year, $t,
document("sbook.xml")//title) let
$a := for $d2 in timber-mlca ($k,document("sbook.xml")//article,
$y2, document("sbook.xml")//year) where
$y1 = $y2 return
$k where
$b/price < 60 and $b/price > 20 return
<result> {$t} {$a} </result> |
Logical Plan
A logical plan is a query composed of logic algebra operators. It can be generated from a given query inXQuery by XqueryParser, and transformed into corresponding physical plan(s) by Query Optimizer of Timber; the one determined with lowest cost will be executed against the database.
Timber supports any logical plan satisfying the Logical Algebra grammar.
Example 10. A sample logical plan (corresponding to the simple query in Example 1)
|
//
Logical plan //
number of Pattern Tree Nodes, Pattern Trees and Process Tree Nodes 8 3 6 //
list of pattern tree nodes //
list of nodes for pattern tree 5 7
C_REFERENCE 6 SUBTREE //
list of nodes for pattern tree 6 1000
REFERENCE 3 PARENT - 6
ELEMENT sbook.xml title NULL "" PARENT * //
list of nodes for pattern tree 1 1
DOCUMENT sbook.xml ANCS - 2
ELEMENT sbook.xml books NULL "" PARENT - 3
ELEMENT sbook.xml book NULL "" PARENT - 4
ELEMENT sbook.xml price LTN "60" PARENT - 5
ELEMENT sbook.xml price GTN "20" PARENT - //
list of pattern trees //
pattern tree 5
1 7 CONSTRUCT_TREE 7
-1 //
pattern tree 6
2 1000 PATTERN_TREE 1000
-1 6
1000 //
pattern tree 1
5 1 PATTERN_TREE 1
-1 2
1 3
2 4
3 5
3 //
list of process tree nodes 10
CONSTRUCT 5 11
SORT 1 3 KEY ASCENDING GREATEST 9
SELECT 6 7
DUPLICATE_ELIMINATION ID 1 6
PROJECT 2 1 3 4
SELECT 1 //
process tree 0
6 10 10
-1 11
10 9
11 7
9 6
7 4 6 |
Physical Plan
A physical plan is a query composed of evaluation iterators (physical operators) that actually access database, and combine and reconstruct information from the database. In a physical plan, the evaluation operators are listed in a depth-first preorder manner- first the operator then its inputs. Each Iterator is on a separate line. A line in the file that starts with a �*� is a comment line and will be ignored during the query process. The evaluator interface is case-sensitive. If it�s capital here it should be capital in the file. For full specification of all iterators supported by Timber please see Physical Algebra.
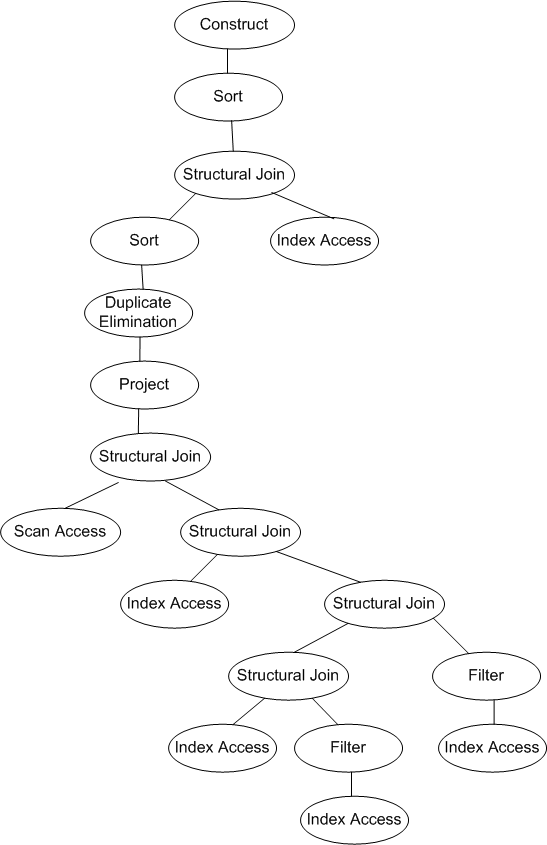
Example
11. A sample
physical plan (corresponding to the simple query in Example 1)
|
******************************************************** *Query: *
for $b in document("sbook.xml")/books/book *
where $b/price < 60 and $b/price > 20 *
return $b/title *******************************************************
s,1,1,C,R,7,6,0,S R,-1,K,1,3,A,E,X J,a,3,6,-1,-1,-1,P,B,N R,-1,K,1,3,A,B,X D,TR,1,-1,NULL,1 P,2,1,3,1 J,A,1,2,-1,-1,-1,P,B S,1,sbook.xml,0,DOCUMENT_NODE,THISNODE,1,1,XMLFILENAME,EQ,STR,sbook.xml,0,0,0 J,A,2,3,-1,-1,-1,P,B I,2,index_sbook_elementtag,sbook.xml,GIST,INT,books J,A,3,5,-1,-1,-1,P,B J,A,3,4,-1,-1,-1,P,B I,3,index_sbook_elementtag,sbook.xml,GIST,INT,book f,1,1,AO,T,4,-1,NULL,LTN,C,-1,60.000000,NULL I,4,index_sbook_elementtag,sbook.xml,GIST,INT,price f,1,1,AO,T,5,-1,NULL,GTN,C,-1,20.000000,NULL I,5,index_sbook_elementtag,sbook.xml,GIST,INT,price I,6,index_sbook_elementtag,sbook.xml,GIST,INT,title
|
Example 12. Query evaluation tree for the physical plan in example 11
Last updated: 07/19/2004